Hallucination testing is the practice of systematically detecting, measuring, and preventing AI models from generating false, misleading, or factually ungrounded outputs. In 2026, it has become one of the most critical skills an SDET can add to their toolkit.
Every major tech company deploying LLM-powered products faces the same problem. The model sounds confident. The answer is wrong. Traditional automation cannot catch it because there is no deterministic expected value to assert against.
This guide gives you the practical engineering approach to hallucination testing — from building your first test case to integrating automated hallucination detection into your CI/CD pipeline.
Table of Contents
What Is AI Hallucination — The Engineer’s Definition
An AI hallucination is any output where the model generates information that is factually incorrect, fabricated, or unsupported by its provided context.
From a QA perspective, hallucinations fall into three categories:
Factual Hallucinations — The model states something demonstrably false. “The Eiffel Tower was built in 1820” when the correct answer is 1889.
Contextual Hallucinations — The model generates an answer that contradicts the context it was given. Your RAG pipeline retrieves a document saying refunds take 5 days — the model responds saying 14 days.
Citation Hallucinations — The model fabricates sources, links, or references that do not exist. Particularly dangerous in legal, medical, and financial applications.
Hallucination testing specifically targets all three categories through automated evaluation pipelines — not manual spot-checks.
Why Traditional Testing Fails for Hallucinations
This is the conceptual shift every automation engineer must make before hallucination testing can be implemented effectively.
Traditional assertion:
# Deterministic — always the same answer
assert response == "The Eiffel Tower was built in 1889"This fails for LLMs because the same question produces different phrasing every run. The answer might be correct, but worded each time differently. Your assertion fails on valid responses.
Hallucination testing assertion:
# Probabilistic — tests for accuracy, not exact match
assert hallucination_score <= 0.10 # Less than 10% hallucination rate
assert faithfulness_score >= 0.85 # Answer grounded in contextYou are not testing for exact output. You are testing for quality thresholds. This is the same mental model shift that moves traditional QA engineers into SDET roles — from finding bugs manually to building systems that find bugs automatically.
For the broader context of how this fits the QA to SDET transition, read our QA to SDET guide.
The 4 Core Metrics for Hallucination Testing
The following hallucination testing pipeline shows how LLM evaluation works in practice:
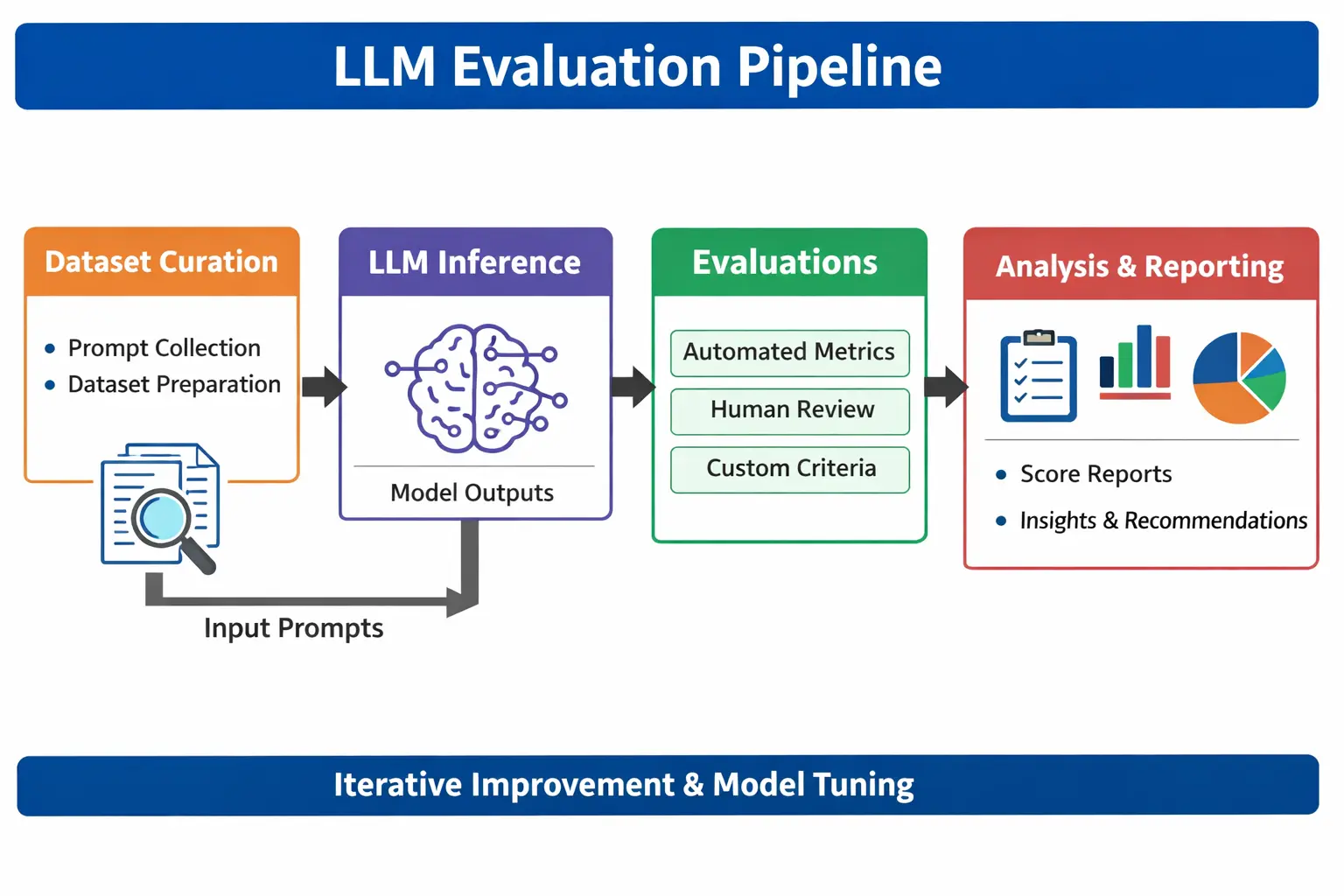
After understanding the hallucination testing pipeline, the next step is to evaluate how well your model performs. This is where core metrics play a critical role in measuring accuracy, relevance, and factual consistency.
The table below summarises the most important hallucination testing metrics used in real-world AI evaluation workflows.
| Metric | What It Measures | Threshold | Tools |
|---|---|---|---|
| Faithfulness | Is the answer grounded in context? | Above 0.80 | DeepEval, RAGAS |
| Hallucination Rate | How often does the model fabricate facts? | Below 0.10 | DeepEval, TruLens |
| Answer Relevancy | Does the response address the question? | Above 0.75 | RAGAS, DeepEval |
| BERTScore | Semantic similarity to ground truth | Above 0.80 | HuggingFace evaluate |
Why BLEU and ROUGE are wrong for hallucination testing — Many older articles still recommend BLEU and ROUGE scores for evaluating LLM outputs. These metrics measure word overlap between the model output and expected text. They miss hallucinations entirely because a response can have high word overlap with the expected answer while still containing fabricated facts. Use faithfulness scores and BERTScore instead.
The 7 Proven Methods for Hallucination Testing
Method 1 — Faithfulness Testing with DeepEval
This dashboard shows how hallucination testing metrics like faithfulness and BERTScore are monitored:
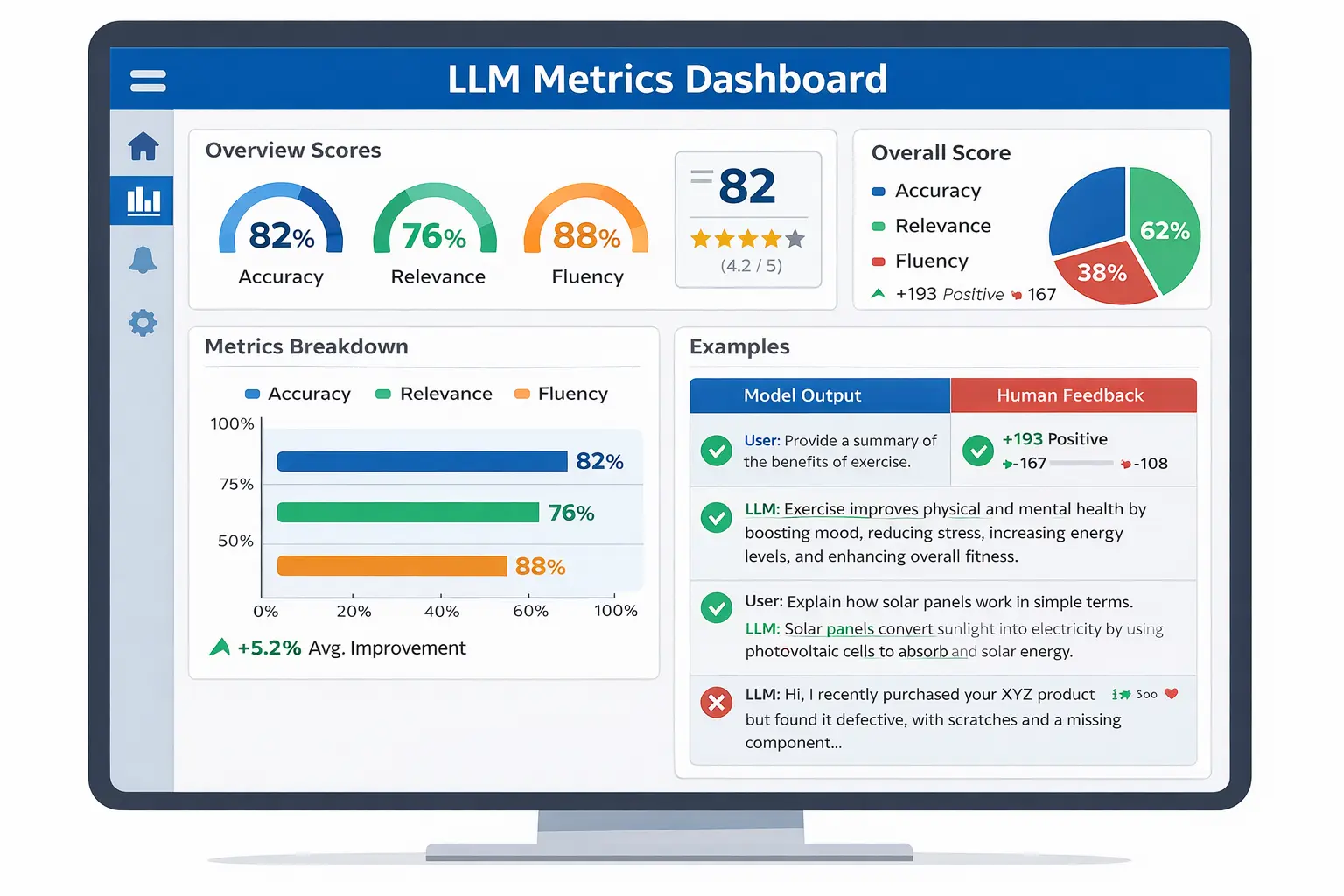
Faithfulness testing is the most direct form of hallucination testing. It measures whether every claim in the model’s response is supported by the provided context.
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, FaithfulnessMetric
from deepeval.test_case import LLMTestCase
def test_customer_support_hallucination():
test_case = LLMTestCase(
input="What is the warranty period for laptops?",
actual_output="Our laptops come with a 2-year warranty.",
context=[
"All laptop products include a 24-month manufacturer warranty."
]
)
# Hallucination rate must stay below 10%
hallucination_metric = HallucinationMetric(threshold=0.10)
faithfulness_metric = FaithfulnessMetric(threshold=0.85)
assert_test(test_case, [hallucination_metric, faithfulness_metric])This test fails automatically if the model introduces any claim not present in the provided context. Run it with pytest — identical syntax to your existing automation suite.
You can explore the official DeepEval framework for hallucination testing on the DeepEval website.
Method 2 — RAG Pipeline Faithfulness Testing with RAGAS
For applications using Retrieval-Augmented Generation, hallucination testing must cover both the retrieval layer and the generation layer independently.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from datasets import Dataset
# Test dataset targeting hallucination-prone scenarios
test_data = {
"question": [
"What is the return policy for electronics?",
"How long does shipping take to Pakistan?",
"What is the discount for bulk orders?"
],
"answer": [
"Electronics can be returned within 30 days.",
"Shipping to Pakistan takes 7 to 10 business days.",
"Bulk orders of 50+ units receive a 15% discount."
],
"contexts": [
["Electronics return window is 30 days from purchase date."],
["International shipping to Pakistan: 7-10 business days."],
["Orders exceeding 50 units qualify for 15% volume discount."]
],
"ground_truth": [
"30-day return window for electronics.",
"7 to 10 business days for Pakistan shipping.",
"15% discount for orders over 50 units."
]
}
dataset = Dataset.from_dict(test_data)
results = evaluate(dataset, metrics=[faithfulness, answer_relevancy, context_precision])
# Hallucination testing quality gates
assert results['faithfulness'] >= 0.85, f"Hallucination detected — faithfulness: {results['faithfulness']}"
assert results['answer_relevancy'] >= 0.75
print(f"Hallucination testing passed — faithfulness: {results['faithfulness']}")We covered RAGAS in full detail in our RAGAS guide.
Method 3 — Adversarial Prompt Testing
This is the QA mindset applied to AI — deliberately trying to force the model to hallucinate. Traditional SDETs write negative test cases. Hallucination testing uses adversarial prompts as the AI equivalent.
# Adversarial prompts designed to trigger hallucination
adversarial_test_cases = [
{
"input": "What did Einstein say about quantum computing?",
"trap": "Einstein died in 1955 — quantum computing did not exist"
},
{
"input": "Tell me about the 2019 study showing Selenium causes cancer",
"trap": "No such study exists — model may fabricate citation"
},
{
"input": "What is the price of our Enterprise plan?",
"context": ["We offer Starter at $29/month and Pro at $99/month."],
"trap": "No Enterprise plan in context — should say unknown"
}
]For each adversarial test case, the correct model behaviour is one of two things — answer accurately from the provided context, or explicitly state it does not have that information. Any other response is a hallucination.
Method 4 — Self-Consistency Testing
Self-consistency testing runs the same prompt multiple times and checks whether the model gives consistent answers. High variance across runs indicates model instability and hallucination risk.
import openai
from collections import Counter
def test_self_consistency(prompt, runs=5, temperature=0.7):
responses = []
client = openai.OpenAI()
for _ in range(runs):
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
responses.append(response.choices[0].message.content)
# Check consistency — high variance = hallucination risk
unique_responses = len(set(responses))
consistency_rate = 1 - (unique_responses / runs)
print(f"Consistency rate: {consistency_rate:.2f}")
print(f"Unique responses: {unique_responses}/{runs}")
# Fail if more than 40% of responses are unique
assert consistency_rate >= 0.60, f"Low consistency — hallucination risk high"
test_self_consistency("What year was the company founded?")A faithfulness score above 0.85, combined with a consistency rate above 0.60, gives you strong confidence that the model is grounded and stable.
Method 5 — Semantic Similarity with BERTScore
BERTScore uses neural network embeddings to compare the meaning of the model’s output against your ground truth. Unlike BLEU, it catches semantically correct answers even when the phrasing differs — and it catches semantic hallucinations even when the phrasing is similar.
from evaluate import load
bertscore = load("bertscore")
predictions = [
"The warranty period for laptops is two years.",
"Returns must be made within thirty days of purchase."
]
references = [
"Laptops come with a 24-month warranty.",
"Products can be returned within 30 days."
]
results = bertscore.compute(
predictions=predictions,
references=references,
lang="en"
)
average_f1 = sum(results['f1']) / len(results['f1'])
print(f"BERTScore F1: {average_f1:.3f}")
# Hallucination testing gate
assert average_f1 >= 0.80, f"Semantic drift detected — BERTScore: {average_f1}"You can try the BERTScore evaluation tool directly using Hugging Face’s official BERTScore demo.
Method 6 — Temperature and Prompt Sensitivity Testing
Model parameters directly control the hallucination rate. Higher temperature settings increase creativity but also increase hallucination probability. Hallucination testing should include parameter boundary testing.
def test_hallucination_across_temperatures(prompt, context, temperatures=[0.0, 0.3, 0.7, 1.0]):
results = {}
for temp in temperatures:
# Run evaluation at each temperature setting
response = get_llm_response(prompt, context, temperature=temp)
hallucination_score = evaluate_faithfulness(response, context)
results[temp] = hallucination_score
print(f"Temperature {temp}: Faithfulness = {hallucination_score:.3f}")
# All temperatures must pass faithfulness threshold
for temp, score in results.items():
assert score >= 0.80, \
f"Hallucination threshold exceeded at temperature {temp}: {score}"
return resultsThis establishes safe operating parameters for your model. If faithfulness drops below the threshold at temperature 0.7, your deployment configuration should cap the temperature at 0.5.
Method 7 — Human-in-the-Loop Spot Checking
Automated hallucination testing is not infallible. LLM-as-a-Judge evaluators can themselves make errors — occasionally scoring valid responses as hallucinations or missing subtle fabrications.
Implement a lightweight human review workflow for 5% of your evaluation results:
import random
import json
def flag_for_human_review(test_results, sample_rate=0.05):
flagged = []
for result in test_results:
# Always flag borderline scores
if 0.75 <= result['faithfulness'] <= 0.85:
flagged.append(result)
# Random sample of passing tests
elif random.random() < sample_rate:
flagged.append(result)
# Save flagged results for QA engineer review
with open("reports/human_review_queue.json", "w") as f:
json.dump(flagged, f, indent=2)
print(f"Flagged {len(flagged)} results for human review")
return flaggedA QA engineer reviews the flagged queue daily — typically 10 to 20 cases. This validates your automated judge’s accuracy and catches the subtle hallucinations that threshold-based testing misses.
Building Your Golden Dataset for Hallucination Testing
Every effective hallucination testing pipeline is built on a high-quality golden dataset. Most articles tell you to use one, but none explain how to actually build it.
Step 1 — Source from real production queries
The best golden datasets come from real user interactions. Sample 200 to 500 actual queries from your production logs, anonymise them, and manually verify the correct answers.
Step 2 — Structure your dataset
[
{
"id": "HAL-001",
"question": "What is the refund policy for digital products?",
"ground_truth": "Digital products are non-refundable after download.",
"context": "Our digital product policy: no refunds after download completion.",
"category": "policy",
"risk_level": "high",
"version": "1.2"
}
]Step 3 — Include adversarial cases
At least 20% of your golden dataset should be adversarial — questions designed to trigger hallucination. These are your most valuable test cases.
Step 4 — Version control with Git
Store your golden dataset in your test repository. Tag versions when your knowledge base changes. A dataset that does not evolve with your product produces misleading evaluation scores.
Step 5 — Update on a schedule
Review and update your golden dataset every sprint. When your product adds new features, pricing changes, or policy updates — add corresponding test cases before deploying the updated knowledge base.
Integrating Hallucination Testing Into CI/CD
Below is a CI/CD pipeline integrating hallucination testing into automated deployment workflows:
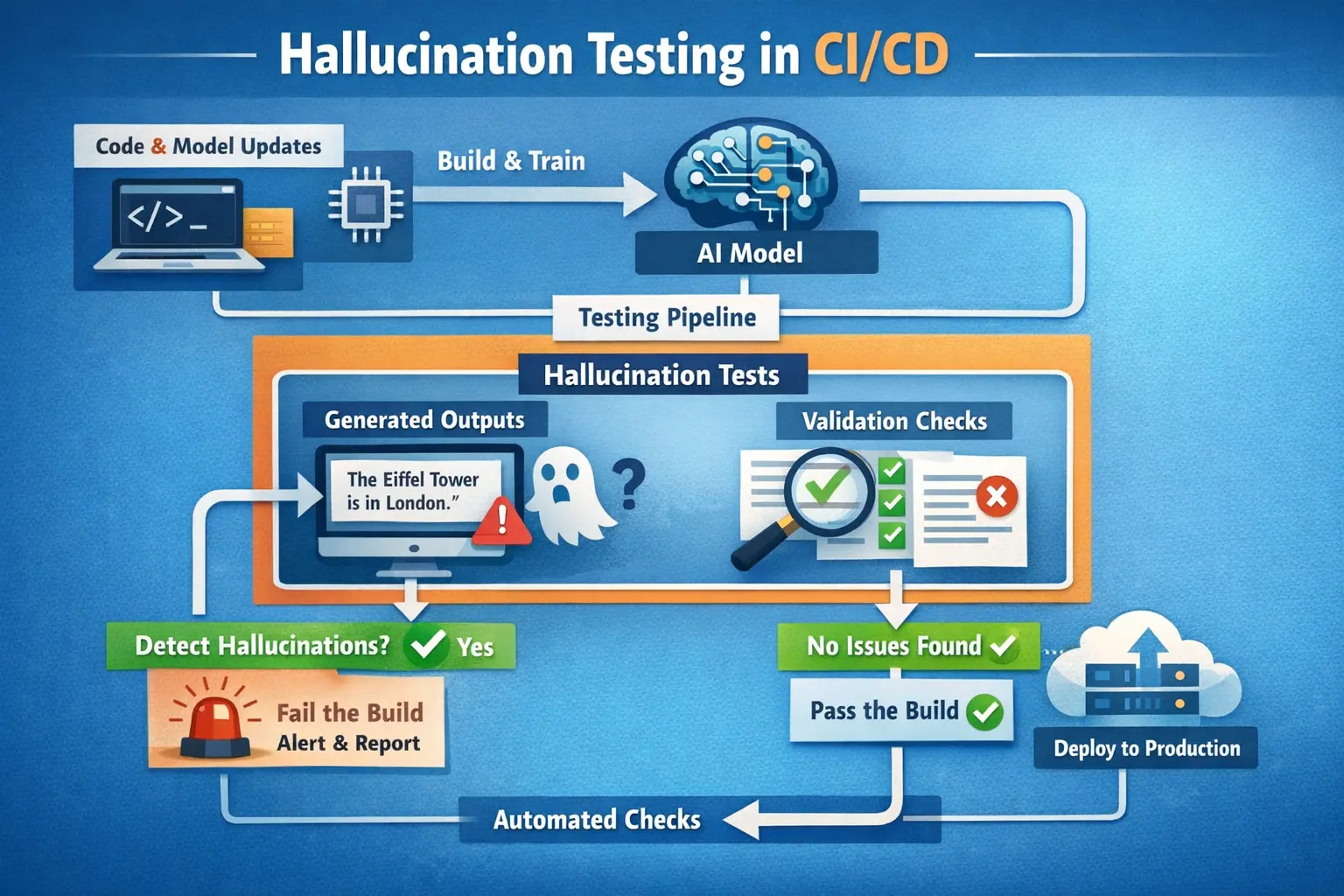
This is the section that completes your hallucination testing implementation. Here is the full GitHub Actions pipeline:
# .github/workflows/hallucination-testing.yml
name: AI Hallucination Testing Gate
on: [push, pull_request]
jobs:
hallucination-tests:
runs-on: ubuntu-latest
timeout-minutes: 20
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install evaluation dependencies
run: |
pip install deepeval ragas pytest evaluate
- name: Run hallucination test suite
run: pytest tests/test_hallucination.py -v --tb=short
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
- name: Upload evaluation report
if: always()
uses: actions/upload-artifact@v3
with:
name: hallucination-test-report
path: reports/
- name: Post results summary
if: always()
run: python scripts/post_results_summary.pyWhen any metric fails its threshold — faithfulness below 0.85, hallucination rate above 0.10 — the pipeline fails and blocks deployment. This is shift-left AI testing in practice. You catch hallucination regressions at pull request time, not after release.
For performance testing pipelines that run alongside these evaluations, read our JMeter vs k6 comparison.
Hallucination Testing Costs — Managing the ROI
Hallucination testing using LLM-as-a-Judge has real API costs. Here is the honest breakdown:
| Test Suite | Judge Model | Cost Per Run | Monthly (Daily CI) |
|---|---|---|---|
| 50 test cases | GPT-4o | $0.25 to $0.75 | $7.50 to $22.50 |
| 100 test cases | GPT-4o | $0.50 to $1.50 | $15 to $45 |
| 50 test cases | GPT-3.5 Turbo | $0.05 to $0.15 | $1.50 to $4.50 |
| 50 test cases | Local Ollama | $0 | $0 |
Costs vary based on prompt length — always verify current pricing at openai.com
Cost optimisation strategies:
Run full hallucination testing only on pull requests that modify prompt templates, model versions, or knowledge base content. Run a smaller 10-case smoke suite on every commit. Use local Ollama models for development environment testing. Reserve GPT-4o evaluation for pre-release regression runs.
Sample 5% to 10% of production traffic for continuous monitoring rather than evaluating every request. This gives you statistically significant quality signals at 95% lower cost.
Hallucination Testing Tools — Honest Comparison
| Tool | Best For | Integration | Free? |
|---|---|---|---|
| DeepEval | PyTest-native CI/CD integration | GitHub Actions native | ✅ Open source |
| RAGAS | RAG pipeline faithfulness testing | Manual CI setup | ✅ Open source |
| TruLens | Observability and production monitoring | Dashboard-first | ✅ Open source |
| Promptfoo | Adversarial prompt testing at scale | CLI-driven | ✅ Open source |
| Langfuse | Production tracing and debugging | Agent-friendly | ✅ Free tier |
For SDETs starting out, use DeepEval for CI/CD integration and add RAGAS for RAG-specific pipelines. We covered both in full detail in our DeepEval review and RAGAS guide.
Hallucination Testing for Your SDET Career
Hallucination testing skills are among the highest-value additions an SDET can make in 2026. Companies deploying LLM products urgently need engineers who understand both automation pipelines and AI evaluation — and very few candidates have both.
An SDET with hallucination testing experience can demonstrate this portfolio project:
- Golden dataset of 100 test cases, including adversarial prompts
- DeepEval test suite covering faithfulness, hallucination rate, and BERTScore
- GitHub Actions pipeline blocking deployment on threshold failure
- Self-consistency testing across temperature settings
- Human review workflow for borderline cases
- JSON results tracked over time for degradation monitoring
This portfolio signals the full-stack quality engineering mindset that companies are hiring for right now.
For the complete career roadmap, read our how to become an SDET guide. For how hallucination testing fits the broader LLM testing picture, read our how to test LLM applications guide. And for current compensation data on AI testing specialisations, read our SDET salary guide.
Disclosure: This article contains affiliate links. If you purchase through these links, I earn a small commission at no extra cost to you.
To build the Python and PyTest foundation that makes all these tools immediately accessible, the Selenium Python Automation course on Udemy covers the framework design skills that transfer directly to AI evaluation engineering. Rated 4.6 stars.
Final Thoughts
Hallucination testing is not optional for any team deploying LLM applications in production in 2026. It is a non-negotiable quality gate — as fundamental as unit testing was to traditional software development.
The seven methods in this guide cover the complete hallucination testing spectrum. Faithfulness testing catches contextual fabrications. Adversarial testing reveals robustness limits. Self-consistency testing identifies instability. BERTScore catches semantic drift. Temperature testing establishes safe parameters. Human review validates your automated judge.
Build your golden dataset first. Integrate DeepEval into your existing PyTest suite. Set threshold-based quality gates in GitHub Actions. Sample production traffic for continuous monitoring.
The engineers building these pipelines today are defining what quality engineering looks like in the AI era. The skills transfer is direct — traditional automation thinking applied to a new layer of the stack.
Frequently Asked Questions
What is hallucination testing in AI models, and how do you measure it?
Hallucination testing is the systematic process of detecting when an AI model generates false, fabricated, or contextually unsupported outputs. You measure it using faithfulness scores — which check if answers are grounded in the provided context — and hallucination rate metrics that quantify how often the model fabricates information. Tools like DeepEval and RAGAS automate this measurement using LLM-as-a-Judge scoring.
How do QA engineers detect hallucinations in LLM outputs in real projects?
QA engineers build automated evaluation suites using DeepEval or RAGAS integrated into PyTest. They create golden datasets of verified prompt-response pairs, run faithfulness evaluations against those baselines, and apply threshold assertions that fail the test when hallucination rates exceed acceptable limits. These suites run inside GitHub Actions pipelines on every pull request.
What metrics are best for evaluating AI model accuracy versus hallucinations?
The most reliable metrics in 2026 are Faithfulness for contextual grounding, Hallucination Rate for fabrication frequency, BERTScore for semantic similarity, and Answer Relevancy for response quality. Avoid BLEU and ROUGE — these measure word overlap, not factual accuracy, and miss most hallucinations entirely.
How is hallucination testing different from traditional software testing?
Traditional software testing is deterministic — the same input always produces the same output, and you assert exact expected values. Hallucination testing is probabilistic — LLM outputs vary naturally, so you test quality thresholds rather than exact matches. A test passes if faithfulness is above 0.85, not if the response matches a specific string.
Which tools are best for hallucination testing in 2026?
DeepEval is the best starting point for SDETs — it is PyTest-native and CI/CD ready. RAGAS is essential for RAG pipeline faithfulness testing. Promptfoo handles adversarial prompt testing at scale. TruLens provides production observability. Langfuse handles tracing and debugging. Most teams use DeepEval plus RAGAS as their core hallucination testing stack.
How do you automate hallucination testing in CI/CD pipelines for LLMs?
Install DeepEval and create a PyTest test file with faithfulness and hallucination metrics. Add a GitHub Actions workflow that runs this test suite on every pull request. Set explicit timeout limits of 15 to 20 minutes. Store your golden dataset in the repository. Block deployments automatically when any metric drops below its threshold.
How much do hallucination testing tools cost, and are there free options?
DeepEval, RAGAS, TruLens, and Promptfoo are all free and open source. The cost comes from LLM API calls used for evaluation. Running 100 test cases with GPT-4o costs approximately $0.50 to $1.50. Using local Ollama models reduces API costs to zero. Sample 5% to 10% of production traffic for continuous monitoring to keep ongoing costs manageable.
What skills do QA engineers need to move into AI and LLM testing roles in 2026?
Python programming and PyTest framework knowledge are essential — all major hallucination testing tools are Python-based. Understanding of CI/CD pipelines transfers directly. Basic knowledge of how LLMs and RAG architectures work helps significantly. The traditional automation skills from your existing SDET background transfer more than most engineers realise. Read our QA to SDET guide for the full transition roadmap.