RAGAS is an open-source framework for evaluating Retrieval-Augmented Generation pipelines — and understanding this framework has become one of the most valuable skills an SDET can add in 2026.
Most articles about this evaluation approach are written by data scientists for data scientists. This guide is different. It explains RAGAS from a QA engineering perspective — how it fits into your existing automation workflow, how to integrate it into CI/CD pipelines, and how to use it to build automated release gates that block deployments when your AI application starts hallucinating.
Table of Contents
What Is RAG and Why Does It Need Testing?
Here’s a complete visual breakdown of how a RAG pipeline works and how it is evaluated:
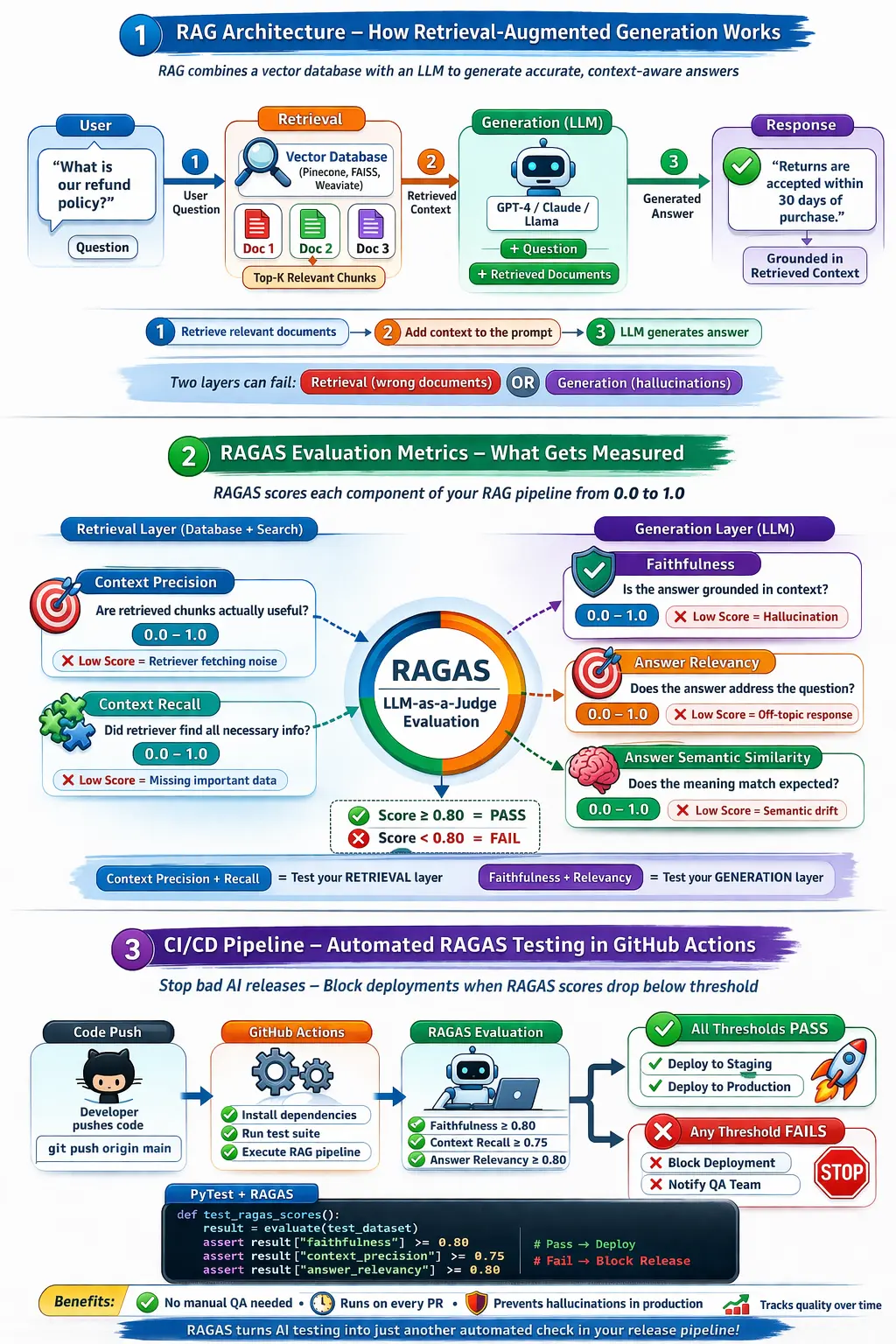
Before explaining RAGAS specifically, you need to understand what RAG is and why it creates a testing problem that traditional automation cannot solve.
RAG — Retrieval-Augmented Generation is the architecture used by most production AI applications in 2026. Instead of relying purely on an LLM’s training data, a RAG system:
- Takes a user question
- Searches a vector database for relevant documents
- Pass those documents as context to the LLM
- The LLM generates an answer grounded in that retrieved context
Customer support bots, internal knowledge assistants, legal document Q&A systems — all of these typically run on RAG architecture.
The testing problem is this — RAG has two layers that can fail independently. The retrieval layer can fetch the wrong documents. The generation layer can hallucinate even when the right documents were retrieved. Traditional automation testing cannot catch either failure because you cannot write a deterministic assertion against a probabilistic output.
This is exactly the problem this framework solves. We covered the broader LLM testing challenge in our guide to testing LLM applications.
What Is RAGAS — The One-Paragraph Answer
RAGAS — Retrieval Augmented Generation Assessment — is an open-source Python framework that evaluates RAG pipeline quality using LLM-as-a-Judge scoring. It measures both the retrieval component and the generation component independently, giving you specific scores for faithfulness, answer relevancy, context precision, and context recall. It works without requiring human-annotated ground truth data for most metrics — making it practical for automation pipelines.
The RAGAS Core Metrics — What Gets Measured
The core metrics and CI/CD integration can be visualized like this:
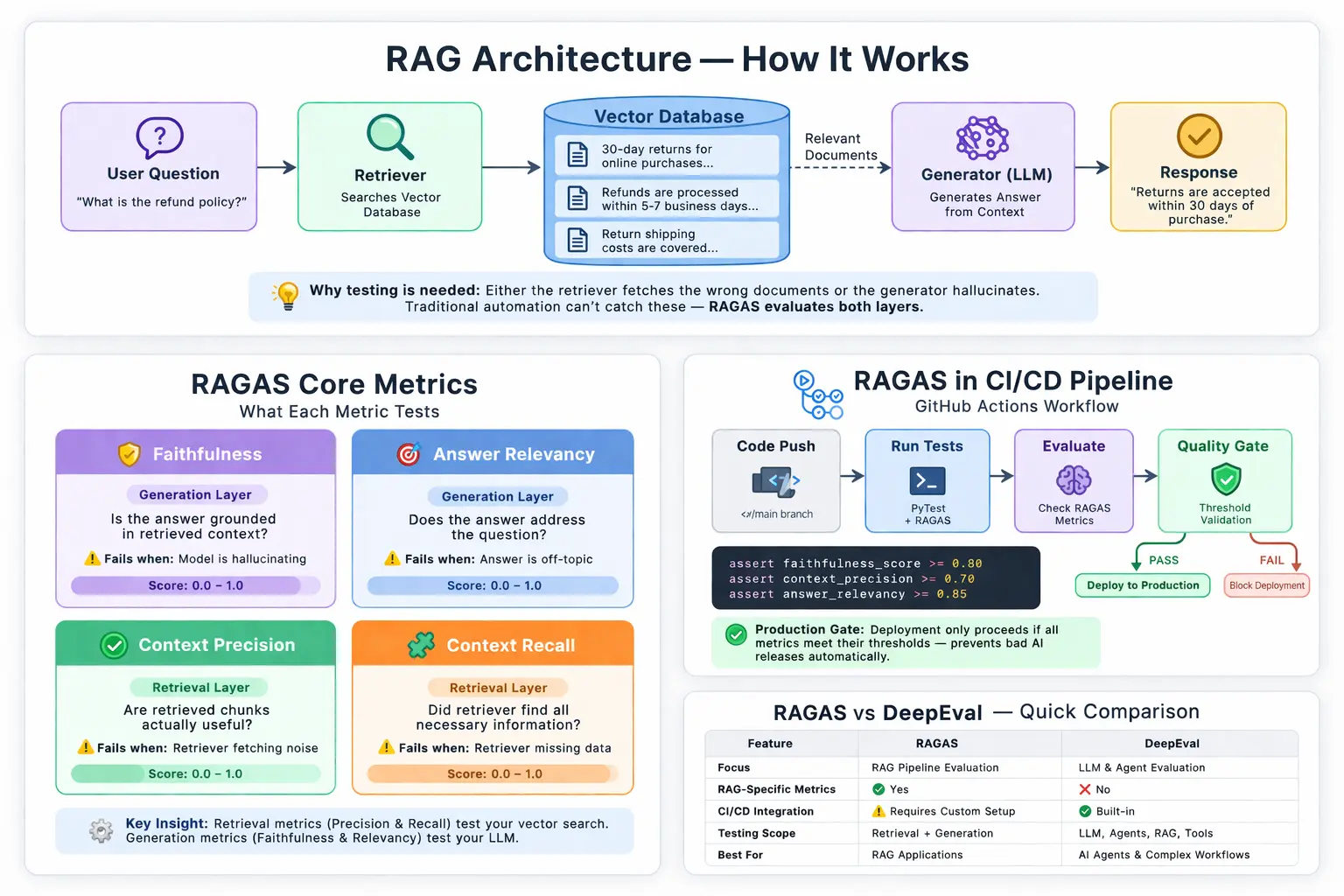
This is the most important section for any QA engineer learning this framework. Understanding what each metric measures tells you exactly what failure mode it detects.
| Metric | What It Tests | Layer | Score Range | Failure Means |
|---|---|---|---|---|
| Faithfulness | Is the answer grounded in retrieved context? | Generation | 0.0 to 1.0 | Model is hallucinating |
| Answer Relevancy | Does the answer address the question? | Generation | 0.0 to 1.0 | Answer is off-topic |
| Context Precision | Are retrieved chunks actually useful? | Retrieval | 0.0 to 1.0 | Retriever fetching noise |
| Context Recall | Did retriever find all necessary information? | Retrieval | 0.0 to 1.0 | Retriever missing data |
| Answer Semantic Similarity | Does meaning match the expected answer? | Generation | 0.0 to 1.0 | Semantic drift occurring |
The critical insight for SDETs — Context Precision and Context Recall test your retrieval layer. Faithfulness and Answer Relevance test your generation layer. A failing faithfulness score with passing context precision means your retriever is working, but your LLM is hallucinating anyway. A failing context recall with passing faithfulness means your LLM is honest, but your vector database is not returning complete information.
This separation of concerns is exactly how traditional automation engineers think about layered testing — UI layer, API layer, database layer. This framework applies the same principle to AI pipelines. For the broader layered testing approach, read our best Selenium frameworks guide.
How RAGAS Works — The Architecture
This framework uses LLM-as-a-Judge to score each metric. A separate evaluator model — typically GPT-4 or Claude — reads your test case and grades the response against your criteria.
The required inputs for evaluation are:
test_case = {
"question": "What is the refund policy?",
"answer": "We accept returns within 30 days.",
"contexts": [
"Our policy allows 30-day returns for all items purchased online."
],
"ground_truth": "Items can be returned within 30 days of purchase."
}It takes these four components and outputs a score between 0 and 1 for each metric. Your threshold becomes your pass/fail gate — exactly like a traditional assertion.
Traditional SDET assertion:
assert response_status == 200 # Pass or failRAGAS threshold assertion:
assert faithfulness_score >= 0.80 # Pass or failSame logic. Different layer. Any SDET who understands PyTest assertions understands these thresholds immediately.
RAGAS in Practice — Complete Code Example
Here is a complete RAGAS evaluation that any QA engineer can run immediately:
# Install: pip install ragas langchain openai
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall
)
from datasets import Dataset
# Your test dataset
test_data = {
"question": [
"What is the refund policy?",
"How do I reset my password?",
"What payment methods are accepted?"
],
"answer": [
"Returns are accepted within 30 days of purchase.",
"Click forgot password on the login page to reset.",
"We accept Visa, Mastercard, and PayPal."
],
"contexts": [
["Our return policy allows 30-day returns for online purchases."],
["Password reset is available via the login page forgot password link."],
["Accepted payment methods include Visa, Mastercard, and PayPal."]
],
"ground_truth": [
"Items can be returned within 30 days.",
"Use the forgot password link on the login page.",
"Visa, Mastercard, and PayPal are accepted."
]
}
dataset = Dataset.from_dict(test_data)
# Run the evaluation
results = evaluate(
dataset,
metrics=[
faithfulness,
answer_relevancy,
context_precision,
context_recall
]
)
print(results)
# Output: {'faithfulness': 0.92, 'answer_relevancy': 0.88,
# 'context_precision': 0.85, 'context_recall': 0.90}
# Apply quality gates
assert results['faithfulness'] >= 0.80, "Faithfulness below threshold — hallucination risk"
assert results['answer_relevancy'] >= 0.75, "Answer relevancy too low"
assert results['context_precision'] >= 0.70, "Retriever returning noisy context"
assert results['context_recall'] >= 0.75, "Retriever missing relevant documents"
print("All quality gates passed — deployment approved")Run this with pytest test_rag_pipeline.py and it integrates directly into your existing PyTest suite. The same runner you use for Selenium and API tests now runs LLM evaluations.
RAGAS vs DeepEval — Which Do You Need?
This question comes up constantly in this context, so here is the honest answer.
They are complementary — not competing.
This framework specialises in RAG pipeline evaluation. It has the most rigorous metrics for testing retrieval quality — context precision and recall — and is the industry standard for that specific use case.
DeepEval has broader LLM testing coverage, including agent testing, multi-turn conversations, and G-Eval for custom metrics. Its CI/CD integration is more polished out of the box.
For most production AI applications in 2026, the optimal stack is this framework for RAG-specific metrics plus DeepEval for agent and general LLM testing. We covered DeepEval in detail in our DeepEval review.
RAGAS vs TruLens — TruLens is a strong alternative with better observability features. It performs better in metric depth and open-source community size. For most SDETs starting out, this framework is the right first choice because the documentation is more engineering-friendly.
Integrating RAGAS Into CI/CD — The Quality Gate Approach
This is the section that separates this article from every other RAGAS guide. Taking this framework out of a Jupyter notebook and into a real deployment pipeline is where the value is for SDETs.
Here is a complete GitHub Actions workflow that blocks deployment when evaluation scores drop below the threshold:
# .github/workflows/rag-quality-gate.yml
name: RAG Pipeline Quality Gate
on: [push, pull_request]
jobs:
ragas-evaluation:
runs-on: ubuntu-latest
timeout-minutes: 20
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install dependencies
run: |
pip install ragas datasets langchain openai pytest
- name: Run evaluation quality gates
run: pytest tests/test_rag_quality.py -v
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
- name: Upload evaluation report
if: always()
uses: actions/upload-artifact@v3
with:
name: ragas-evaluation-report
path: reports/ragas_results.jsonWhen a developer updates the LLM model version, changes prompt templates, or modifies the vector database chunking strategy — this pipeline runs automatically. If faithfulness drops below 0.80, the deployment is blocked. Your CI/CD pipeline now enforces AI quality standards exactly as it enforces code quality standards.
Important pipeline consideration — Evaluation jobs are significantly slower than traditional unit tests. Set explicit timeouts of 15 to 20 minutes for evaluation jobs. Use batched evaluation for large test suites to avoid pipeline hangs.
RAGAS Synthetic Test Data Generation — Save Hours of Manual Work
This feature is almost entirely ignored in other articles about this framework, and it is genuinely valuable for SDETs.
This framework can automatically generate a complete test dataset from your source documents — no manual test case creation required:
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import DirectoryLoader
# Load your source documents
loader = DirectoryLoader("./knowledge_base/")
documents = loader.load()
# Configure generator
generator_llm = ChatOpenAI(model="gpt-4o")
critic_llm = ChatOpenAI(model="gpt-4o")
embeddings = OpenAIEmbeddings()
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Generate 50 test cases automatically
testset = generator.generate_with_langchain_docs(
documents,
test_size=50,
distributions={
simple: 0.5, # Simple factual questions
reasoning: 0.25, # Multi-step reasoning questions
multi_context: 0.25 # Questions requiring multiple documents
}
)
testset.to_pandas().to_csv("golden_dataset.csv", index=False)
print("Generated 50 test cases — saved to golden_dataset.csv")This generates 50 diverse test questions, expected answers, and relevant contexts from your actual knowledge base documents. For a traditional SDET, this saves 3 to 5 hours of manual test case writing per sprint. Version control this CSV in Git alongside your test code and update it whenever your knowledge base changes.
Building an Evaluation Reporting Dashboard
Traditional automation engineers rely on visual reports — Allure, ReportPortal, HTML dashboards. The evaluation outputs JSON, which you can pipe directly into these familiar tools.
import json
import pytest
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
def test_rag_pipeline_with_reporting():
# Run evaluation
results = evaluate(dataset, metrics=[faithfulness, answer_relevancy])
# Save results for reporting dashboard
results_dict = {
"faithfulness": float(results['faithfulness']),
"answer_relevancy": float(results['answer_relevancy']),
"timestamp": "2026-03-29",
"model_version": "gpt-4o-2026-03"
}
with open("reports/ragas_results.json", "w") as f:
json.dump(results_dict, f)
# Track degradation over time
assert results_dict['faithfulness'] >= 0.80
assert results_dict['answer_relevancy'] >= 0.75Store these JSON results over time, and you build a degradation tracking system. When faithfulness trends downward across three consecutive pipeline runs, you get an early warning before it hits the 0.80 threshold and breaks. This is AI observability built with tools every QA engineer already knows.
RAGAS Pricing — Is It Free?
RAGAS, the framework is completely free and open source. There is no paid tier for the evaluation library itself.
The cost comes from the LLM API calls used to run evaluations. Using GPT-4o as your evaluator judge costs approximately:
| Test Suite Size | Estimated Cost with GPT-4o | With GPT-3.5 Turbo |
|---|---|---|
| 10 test cases | $0.05 to $0.15 | $0.01 to $0.03 |
| 100 test cases | $0.50 to $1.50 | $0.10 to $0.30 |
| 500 test cases | $2.50 to $7.50 | $0.50 to $1.50 |
Costs vary based on document length and prompt complexity. Always check current OpenAI pricing at openai.com.
For cost-conscious teams, running this framework with a local model via Ollama reduces API costs to zero. The evaluation quality is slightly lower with smaller local models, but sufficient for development environment testing.
Career Impact for SDET in 2026
Knowledge of this framework is one of the fastest-growing differentiators in SDET job postings in 2026. Companies building RAG-based products — and there are thousands of them — need engineers who understand both automation pipelines and AI evaluation.
An SDET who can build an evaluation suite using this framework, integrate it into GitHub Actions, generate synthetic test data, and track metric degradation over time is genuinely rare. The combination of traditional automation skills plus AI evaluation expertise commands a significant salary premium.
A strong AI testing portfolio project using this framework looks like this:
- A simple RAG application using LangChain and ChromaDB
- RAGAS evaluation suite with all four core metrics
- Synthetic test dataset generated from source documents
- GitHub Actions pipeline blocking deployment on threshold failure
- JSON results tracked over time for degradation monitoring
This project, combined with your traditional framework skills from our best Selenium frameworks guide and career roadmap from our QA to SDET guide, positions you as a full-stack quality engineer — the most in-demand SDET profile in 2026.
For salary data on AI testing specialisations, read our SDET salary guide.
Disclosure: This article contains affiliate links. If you purchase through these links, I earn a small commission at no extra cost to you.
To build the Python and PyTest foundation that makes RAGAS immediately accessible, the Selenium Python Automation course on Udemy covers the framework design and CI/CD integration skills that transfer directly to RAGAS pipeline engineering. Rated 4.6 stars.
Final Thoughts
This framework is one of the most important RAG evaluation frameworks available in 2026, and the one every QA engineer building AI testing skills should learn first. It is free, open source, PyTest-compatible, and directly integrates into the CI/CD pipelines you are already building.
The four core metrics — faithfulness, answer relevancy, context precision, and context recall — give you complete visibility into both layers of your RAG pipeline. When faithfulness drops, your LLM is hallucinating. When context precision drops, your retriever is fetching noise. It tells you exactly which layer failed and exactly how to investigate.
Take this framework out of the Jupyter notebook and into your GitHub Actions pipeline. Set threshold-based quality gates. Generate synthetic test data to build your golden dataset automatically. Track metric trends over time to catch degradation before it reaches production.
This is what shift-left AI testing looks like in practice. And the engineers building it today are defining what SDET roles look like in 2027 and beyond.
For the complete AI testing picture, read our how to test LLM applications guide and our DeepEval review to understand how this framework and DeepEval work together as a complete evaluation stack.
Frequently Asked Questions
What is RAGAS, and how does it evaluate RAG pipelines?
RAGAS — Retrieval Augmented Generation Assessment — is an open-source Python framework that evaluates RAG pipeline quality using LLM-as-a-Judge scoring. It measures faithfulness, answer relevancy, context precision, and context recall by using a separate evaluator model to grade your application’s outputs. It works without requiring human-annotated ground truth data for most metrics, making it practical for automated CI/CD pipelines.
How do you use RAGAS to test retrieval augmented generation systems?
Install the framework with pip install ragas. Create a dataset containing your questions, answers, retrieved contexts, and ground truths. Run the evaluate function with your chosen metrics. Apply threshold assertions to the results — failing the test if any metric drops below your quality threshold. Integrate this PyTest suite into GitHub Actions to block deployments automatically.
Which metrics does RAGAS use for evaluating LLM outputs?
This framework covers five core metrics. Faithfulness measures whether answers are grounded in the retrieved context. Answer Relevancy measures whether responses address the actual question. Context Precision measures whether retrieved chunks are useful. Context Recall measures whether the retriever found all necessary information. Answer Semantic Similarity measures meaning alignment with expected outputs.
Is RAGAS better than traditional LLM evaluation methods for QA?
This framework is significantly better than manual evaluation for scale and consistency. Traditional methods — human review, random sampling — do not scale to CI/CD pipelines. RAGAS provides automated, consistent scoring that integrates directly into deployment workflows. It is not perfect — LLM-as-a-Judge has known calibration limitations — but it is the most practical systematic evaluation approach available in 2026.
How does RAGAS compare to DeepEval for LLM testing?
RAGAS specialises in RAG pipeline evaluation with the most rigorous retrieval metrics available. DeepEval has broader coverage, including agent testing, multi-turn conversations, and custom G-Eval metrics with more polished CI/CD integration. Most production teams use both — RAGAS for RAG-specific metrics and DeepEval for general LLM evaluation. Read our full DeepEval review for the detailed comparison.
Can RAGAS be integrated into CI/CD pipelines for automated testing?
Yes — this is one of RAGAS’s most valuable capabilities for SDETs. RAGAS integrates with GitHub Actions, Jenkins, and GitLab CI using standard PyTest. Set explicit pipeline timeouts of 15 to 20 minutes for evaluation jobs. Use the results JSON to track metric trends over time and generate reports in familiar dashboards like Allure or ReportPortal.
What is the pricing of RAGAS, and is it free or paid?
RAGAS, the framework, is completely free and open source. The cost comes from LLM API calls used for evaluation. Running 100 test cases with GPT-4o costs approximately $0.50 to $1.50. Using local models via Ollama reduces API costs to zero at the cost of slightly lower evaluation quality.
Is learning RAGAS useful for SDET career growth in 2026?
Yes — significantly. Companies building RAG applications urgently need engineers who understand both automation pipelines and AI evaluation. RAGAS proficiency combined with traditional framework skills creates a combination that very few candidates currently have. Check our SDET salary guide for current compensation data on AI testing specialisations.