Agentic testing is the most important shift in QA engineering in 2026 — and most SDETs have not prepared for it yet.
AI coding tools like GitHub Copilot are generating code faster than traditional automation can test it. This gap is the exact problem this approach solves. In this guide, I will walk you through exactly what this testing model is, which tools to use, what it costs, and how to position yourself as the SDET who understands this shift.
This is the complete guide to this approach, built for working QA engineers — not enterprise marketing fluff.
What is agentic testing?
Agentic testing is a goal-driven QA approach where AI agents autonomously plan, execute, and adapt test suites without step-by-step human instruction. Instead of scripting “click button X, then check field Y,” you define an intent like “complete a checkout via Stripe” and the agent determines the execution path. In 2026 it sits on top of frameworks like Selenium and Playwright rather than replacing them.
Agentic Testing — Key Takeaways
- What it is: Goal-driven testing where AI agents plan and execute tests autonomously, sitting on top of Selenium or Playwright, not replacing them.
- vs traditional automation: Traditional is deterministic step-by-step scripts; agentic is stochastic, intent-based, and self-healing.
- vs AI-assisted testing: AI-assisted helps you write tests faster (human stays in the loop); agentic removes the human from the execution loop entirely.
- The architecture: four layers — Planner agent, Executor agents, Analyzer agent, and Human-in-the-Loop (the SDET as quality orchestrator).
- The new SDET role: Quality Orchestrator — prompt engineering for test suites, guardrail design, agent observability, and cost management.
- Cost reality: a complex end-to-end agent test costs ~$0.50-$2.00 per run; computer-use agents cost 10-50x more than text/DOM agents.
- Top failure mode: false confidence — agents producing green reports that missed critical paths. Fix by requiring coverage maps, not just pass/fail counts.
Table of Contents
What Is Agentic Testing?
Agentic testing is the next evolution of test automation. It moves from scripted execution to autonomous goal-driven quality engineering.
Traditional automation is deterministic — you write step-by-step scripts that execute identically every time. This approach is stochastic — AI agents reason about the application, adapt to changes, and choose execution paths dynamically.
In 2026, over 85% of enterprise QA teams report that AI code generation has created a testing bottleneck. Developers ship code faster than automation engineers can write tests for it. This model directly addresses this confidence gap.
Agentic Testing vs Traditional Automation
| Feature | Traditional Automation | Agentic Testing |
|---|---|---|
| Execution | Step-by-step scripts | Goal-driven execution |
| Maintenance | High (locator fixes) | Low (self-healing) |
| Flexibility | Low | High |
| Test Design | Manual | Intent-based |
| Cost Model | Fixed | Variable (LLM tokens) |
| Human Effort | High scripting effort | Quality orchestration |
AI-Assisted vs Agentic Testing — The Critical Difference
This is the most misunderstood concept in QA in 2026. The distinction matters for your career.
AI-assisted testing means AI helps you write tests faster. GitHub Copilot suggests test code. Mabl auto-generates locators. You still control every step. The human writes the script — AI just speeds it up.
This approach means AI agents autonomously run, adapt, and fix tests. You define a goal. The agent plans the execution, handles UI drift, retries on failure, and logs decisions without you touching a line of code.
The practical difference: AI-assisted testing reduces the time to write a test from 2 hours to 20 minutes. This model removes the human from the execution loop entirely.
For SDETs, the career implication is clear. AI-assisted skills are becoming table stakes. Skills in this approach — specifically how to define goals, set guardrails, and evaluate agent decisions — are the differentiator in 2026.
Who Should Use Agentic Testing in 2026?
Agentic testing is not for every team — but it is critical for:
- SaaS teams releasing features daily or multiple times per week
- QA teams struggling with flaky Selenium or Playwright tests
- Engineering teams using AI-generated code (Copilot, LLMs)
- SDETs who want to future-proof their careers
- Startups that need fast coverage without large QA teams
If your test suite is slowing down releases, this approach is no longer optional — it becomes a competitive advantage.
How Agentic Testing Works — The Architecture
Understanding the architecture is what separates SDETs who can implement this architecture from those who just talk about it.
This system has four layers:
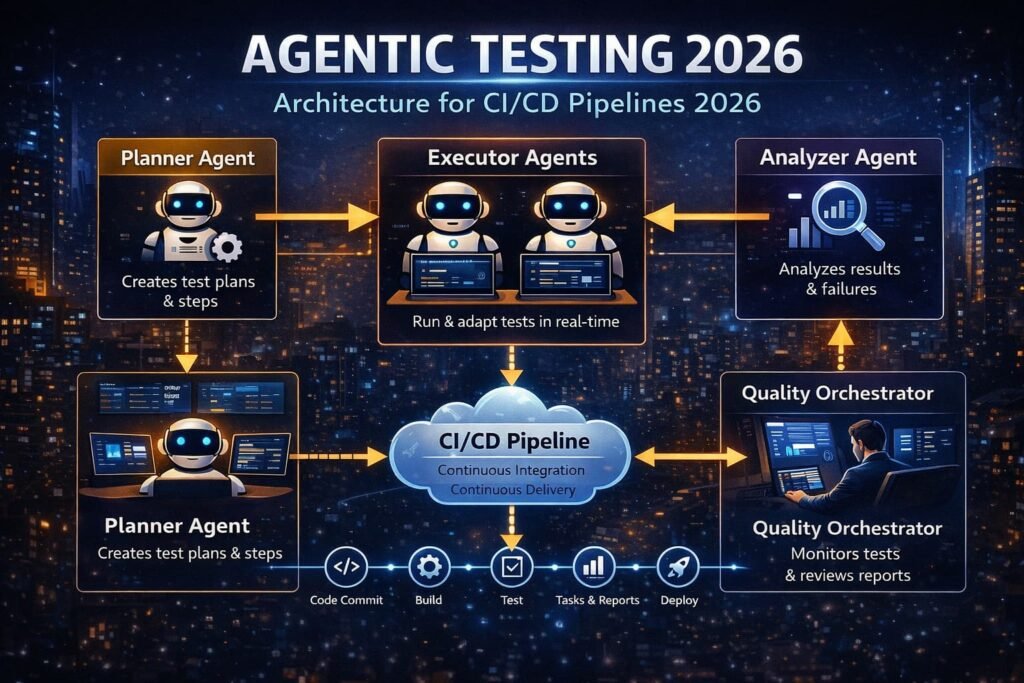
Layer 1 — The Planner Agent Receives the high-level goal (“test the checkout flow”) and breaks it into subtasks. Uses an LLM to reason about the application structure, identify required steps, and assign them to executor agents.
If you’re new to testing AI systems, start with our guide to testing LLM applications.
Layer 2 — The Executor Agents Carry out individual tasks — navigating the UI, calling APIs, and validating database state. Each executor uses vision models or DOM parsing to understand the current state of the System Under Test (SUT).
Layer 3 — The Analyzer Agent Reviews execution results. Classifies failures as real bugs, flaky tests, or environment issues through intelligent triage. Routes failures to the correct code owner automatically.
Layer 4 — Human-in-the-Loop (HITL) The quality orchestrator — the SDET — reviews agent decisions, updates guardrails, and validates that agent-reported coverage is genuine. This is the layer that prevents false confidence — where AI generates clean-looking but shallow test reports.
In real projects, these layers run inside your existing CI/CD pipeline. Agentic tools sit on top of Selenium, Playwright, or Cypress — they augment your framework, not replace it.
The SDET Role in 2026 — Quality Orchestrator
Agentic testing does not eliminate SDET jobs. It transforms them.
Remote SDET demand grew over 40% since 2023. But the job description is changing. In 2025, SDET roles focused on framework design and automation scripting. In 2026, the highest-paying SDET roles focus on quality orchestration — managing fleets of AI agents rather than writing individual test scripts.
The Quality Orchestrator role requires four new skills:
1. Prompt engineering for test suites Writing intent-based test instructions that agents can execute reliably. “Complete a guest checkout for a $49 item using Visa” is better than “test the checkout button.” Precision in goal definition directly determines agent accuracy.
2. Guardrail design Defining what agents are allowed and not allowed to do. This is critical for security. An agent with unrestricted access to a staging environment can accidentally trigger emails, charge test cards, or modify production data. Blast radius and access creep — the security risks of over-permissioned agents — are real problems in 2026.
3. Agent observability Debugging agents when they make wrong decisions. Traditional debugging checks pass/fail. Agent observability tracks the entire execution path — every tool call, reasoning step, and decision branch. Tools like Openlayer and Maxim AI are built specifically for this.
4. Cost management These tools consume LLM tokens on every test run. A single complex end-to-end agent test can cost $0.50–$2.00 per run. At 500 runs per CI/CD pipeline per day, that is $250–$1,000 daily. Understanding cost per test run is now an SDET responsibility.
Agentic Testing Tools in 2026
| Tool | Type | Best For | Cost Model |
|---|---|---|---|
| Mabl Agentic Tester | Managed platform | Enterprise UI testing | Per seat |
| QA Wolf | Managed service | Fully autonomous regression | Per run |
| Scandium | Self-hosted | Teams wanting control | Open core |
| BetterQA | Cloud platform | API + UI combined | Per run |
| AutoGen (Microsoft) | Open source framework | Custom agent pipelines | Free + LLM costs |
| Playwright + LLM | DIY approach | SDETs building custom agents | Free + LLM costs |
For evaluating the LLM outputs these agents produce, see our DeepEval vs RAGAS vs TruLens guide.
Choosing the right approach:
For enterprise teams — managed platforms like Mabl or QA Wolf handle infrastructure, observability, and guardrails out of the box. Higher cost, faster setup.
You can read a full breakdown in our detailed Mabl review.
For SDETs building portfolio projects — the DIY approach using Playwright combined with an LLM API (OpenAI or Anthropic) gives you full control and demonstrates genuine engineering depth. This is the highest-value portfolio project you can build in 2026.
For teams on a budget — AutoGen, Microsoft’s open-source multi-agent framework, lets you build custom AI-driven test pipelines at LLM API cost only.
For a deeper comparison of tools, see our best AI testing tools guide.
Multi-Agent Systems — The Advanced Pattern
Single agents handle linear flows. Complex applications need Multi-Agent Systems (MAS) where specialized agents collaborate.
Here is how a production MAS looks for a SaaS application:
Security Agent — Tests authentication boundaries, permission escalation, and API authorization. Runs on every pull request that touches the auth code.
UI Navigation Agent — Handles end-to-end user journey testing. Focuses on critical paths: signup, onboarding, core feature usage, and checkout.
API Contract Agent — Validates that API responses match documented contracts. Flags breaking changes before they reach the UI layer.
Performance Agent — Monitors response times and error rates during test execution. Flags degradation before it becomes a production incident.
These agents coordinate through a CI/CD pipeline using Model Context Protocol (MCP) for secure tool access and OAuth for third-party integrations. Dynamic test selection — agents analyzing code diffs to decide which tests to run — reduces full suite execution time by up to 60%.
The Honest Limitations — When Agentic Testing Fails
This is the section vendor sites will never publish. These are real failure modes you will encounter.
Context Overflow Agents lose track of their initial goal during long, complex execution paths due to LLM token limits. A checkout flow that requires 40+ steps can cause the agent to “forget” the earlier state.
Mitigation: break complex goals into smaller sub-goals with explicit state checkpoints.
Non-Deterministic Outputs: Unlike Selenium, agents may execute a test slightly differently on each run. This makes bug reproduction harder. An agent might find a bug on run 1 but not reproduce it on run 2 because it took a different navigation path.
Mitigation: Implement execution path logging at every step.
False Confidence: The most dangerous failure mode. An agent can generate a green test report that looks comprehensive, but actually missed critical paths because it took the easiest route through the application.
Mitigation: require agents to report coverage maps showing which application states were reached, not just pass/fail counts.
The Integration Bottleneck In 2026, the biggest barrier to scaling this approach is not the AI — it is integrating agents with legacy enterprise systems, complex authentication flows, and non-standard UI frameworks. Shadow DOM, iframes, and canvas elements still cause failures in most agentic tools.
Cost Explosion Computer-use agents that interact with the full browser screen consume 10–50x more tokens than text-based agents.
Mitigation: Use text/DOM-based agents for standard flows and reserve computer-use agents for visual-heavy or inaccessible UI components only.
Real-World Use Case — Agentic Testing in a SaaS CI/CD Pipeline
Here is how a mid-size SaaS team implemented this system in 2026.
The team had 847 automated tests in a Selenium + Pytest framework. Full suite execution took 4.2 hours. They were releasing daily, but the pipeline was blocking deployments.
They implemented a three-agent system on top of their existing framework:
A Dynamic Test Selection Agent analyzed each pull request diff and selected only the tests relevant to the changed code. Average suite reduced from 847 tests to 94 per run. Execution time dropped from 4.2 hours to 28 minutes.
A Triage Agent classified failures automatically. Previously, engineers spent 45 minutes per failed build investigating whether failures were real bugs or flaky tests. The triage agent resolved this in under 2 minutes per failure with 91% accuracy.
A Coverage Gap Agent ran weekly to identify untested application states. It discovered 34 critical user flows that had zero test coverage — flows that human SDETs had missed during manual test planning.
Result: 67% reduction in pipeline block time. Escaped defect rate dropped by 40% in the first quarter. Three SDETs were redeployed from test maintenance to agentic system oversight — the Quality Orchestrator role.
Total additional cost: $180 per month in LLM API fees. ROI was positive within the first week.
Agentic Testing Glossary — Key Terms for SDETs
This glossary covers the high-intent terminology that is becoming standard in SDET job descriptions in 2026.
Observation-Action Loop — The fundamental cycle of an agent: observe the current application state, decide on an action, execute it, observe the result, repeat.
Intent-Based Execution — Defining what to achieve rather than how. The agent determines execution steps autonomously.
Autonomous Self-Healing — An agent detecting a broken locator, adapting to the change, fixing the test, and logging the fix for human review.
Task Orchestration — Coordinating multiple agents to work together on a complex testing objective without human intervention at each step.
Agentic Quality Intelligence — Using agent-collected data to generate insights about application quality beyond simple pass/fail metrics.
Prompt-to-Test Authoring — Writing natural language test intentions that an LLM converts into executable test logic.
Escaped Defect Rate — The percentage of bugs that reach production despite automated testing. The primary success metric for any agentic testing investment.
How to Start With Agentic Testing — SDET Action Plan
Week 1 — Understanding Read the Mabl Agentic Tester documentation and the QA Wolf architecture overview. Understand how intent-based execution differs from your current Selenium approach. No coding required this week.
Week 2 — First Experiment Use Playwright + the OpenAI API to build a simple two-step agent. Define a goal like “log into Sauce Demo and add an item to the cart.” Let the agent plan the steps. Compare its approach to how you would have scripted it manually.
Week 3 — Guardrails Add constraints to your agent. Limit it to read-only actions. Implement execution path logging. Practice identifying when your agent makes a wrong decision and how to correct it through prompt refinement.
Week 4 — Portfolio Project Build a three-agent system using AutoGen on OrangeHRM (the free HR demo app). Assign one agent to UI testing, one to API testing. Document the architecture, cost per run, and failure modes in your GitHub README. This is a portfolio project that no other junior SDET has.
Building agentic testing skills is one of the fastest ways to prepare for modern AI testing roles. If you’re planning your career, follow our AI Test Engineer Roadmap for a complete learning path from QA Engineer to AI Test Engineer.
Final Thoughts
Agentic testing is not a distant future concept. It is running in production pipelines at companies like Tricentis, QA Wolf, and hundreds of enterprise teams right now.
For SDETs, the choice is straightforward. Engineers who understand quality orchestration, guardrail design, and agent observability will command higher salaries and more senior roles in 2026 and beyond. Engineers who only know how to write Selenium scripts will face increasing automation pressure on their own work.
The good news is that this approach builds on top of the skills you already have. Your Selenium knowledge, CI/CD experience, and framework design thinking are the exact foundation this new layer requires.
Start your first agentic experiment this week and focus on building real-world understanding through hands-on practice.
If you want a structured path to becoming an SDET who commands these skills, this Selenium WebDriver with Python course on Udemy covers the automation foundation every agentic testing system is built on.
Disclosure: This article contains affiliate links. If you purchase through these links, I earn a small commission at no extra cost to you.
Frequently Asked Questions
What is agentic testing in QA for AI agents in 2026?
This approach is a goal-driven system where AI agents autonomously plan, execute, and adapt tests without step-by-step human scripting. You define an intent — like “complete a checkout” — and the agent determines execution steps, handles UI drift, and reports results. It sits on top of frameworks like Selenium and Playwright rather than replacing them entirely.
How is agentic testing different from traditional automation testing?
Traditional automation is deterministic — scripts run identically every time. Agentic testing is stochastic — agents reason about the application and adapt dynamically. Traditional automation requires humans to write every step. Agentic testing requires humans to define goals, set guardrails, and review agent decisions. The SDET role shifts from script writer to quality orchestrator.
How do you test AI agents effectively in real-world workflows?
Effective agentic testing requires four practices: writing precise intent-based goals, defining guardrails that limit agent access, implementing execution path logging for observability, and measuring escaped defect rate — not just pass/fail counts. Start with simple two-step agent experiments before tackling complex multi-agent systems.
What are the best agentic testing tools for SDETs in 2026?
For enterprise teams: Mabl Agentic Tester and QA Wolf are production-ready managed platforms. For SDETs building portfolio projects: Playwright combined with an LLM API (OpenAI or Anthropic) gives full control. For open-source pipelines: Microsoft’s AutoGen framework enables custom multi-agent testing at LLM API cost only. Always verify current pricing on official sites.
How much do agentic testing tools cost in 2026?
Managed platforms like Mabl and QA Wolf use per-seat or per-run pricing — expect $500–$2,000 per month for team plans. DIY approaches using Playwright and an LLM API cost $0.50–$2.00 per complex test run at current API rates. Computer-use agents cost 10–50x more per run than text-based agents. Cost per run is now a key SDET responsibility to manage.
How do SDETs design test cases for autonomous AI agents?
Instead of step-by-step scripts, SDETs write intent-based goals with explicit constraints. Example: “As a guest user, complete checkout for one item under $50 using Stripe test card 4242. Do not submit real payment data. Validate order confirmation email is triggered.” Precision in goal definition and guardrail specification directly determines agent accuracy and safety.
What are common challenges in agentic testing and how do you solve them?
The four main challenges are: context overflow (agent forgets initial goal in long flows — fix by breaking goals into sub-goals), non-deterministic outputs (agent takes different paths each run — fix by logging execution paths), false confidence (shallow coverage that looks complete — fix by requiring coverage maps), and cost explosion (token overuse — fix by reserving computer-use agents for visual-only components).
How do you validate decision-making and reasoning in AI agents?
Agent observability tools like Openlayer and Maxim AI track the full execution path — every tool call, reasoning step, and decision branch — rather than just final pass/fail results. This is called Agent Execution Path Evaluation. Without observability, you cannot debug wrong agent decisions or prove that agent-reported coverage is genuine.
Is agentic testing replacing QA engineers?
No — agentic testing is transforming the SDET role into Quality Orchestrator. Remote SDET jobs grew over 40% since 2023. The demand is increasing, not decreasing. Engineers who understand how to manage, govern, and debug AI agent fleets are the highest-value QA professionals in 2026. Pure script-writing skills face increasing pressure, but system-level quality thinking is irreplaceable.
Is agentic testing a good career path for QA engineers in 2026?
Yes — and it is one of the highest-ROI skills you can add right now. Most QA engineers have not started learning agentic testing, which means the skill gap is wide and the early movers will command premium positions. Start by understanding multi-agent architecture, practice prompt engineering for test suites, and build one portfolio project using AutoGen on a public demo application.
Is agentic testing suitable for small QA teams?
Yes — small teams benefit the most from agentic testing because it reduces manual scripting effort. With a proper setup, a small QA team can achieve test coverage comparable to larger teams by leveraging autonomous agents.
Can agentic testing replace Selenium or Playwright completely?
No — agentic testing does not replace frameworks like Selenium or Playwright. Instead, it builds on top of them. These frameworks still handle execution, while agentic systems add intelligence, adaptability, and decision-making on top.